Document Classification using Machine Learning
This project focuses on classifying a collection of documents into predefined categories based on their content. The goal is to automate the process of organizing large volumes of text data efficiently, using machine learning techniques for text classification. The model is trained to categorize documents into one of eight classes, allowing for streamlined document management and easy retrieval.
Project Objective
The objective of this project is to build a text classification model capable of categorizing documents based on their content. The project involves training and evaluating machine learning models to accurately predict the category of each document, enabling the automatic organization of text data.
Steps Involved:
Data Preparation:
- Clean the data by removing noise such as special characters.
- Convert text into a numerical format using techniques like TF-IDF or Count Vectorizer.
Model Selection:
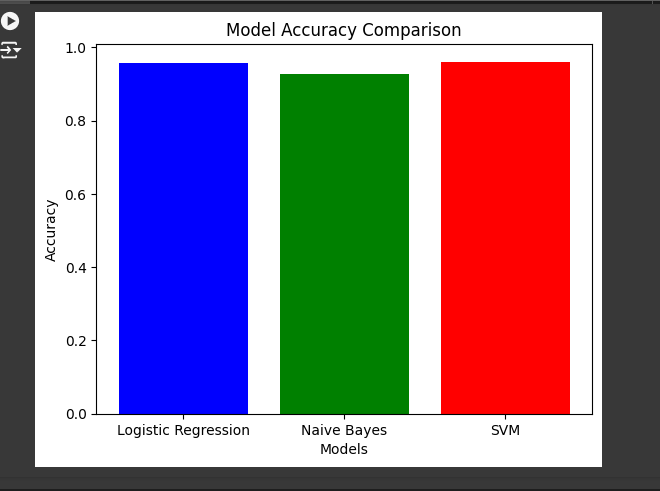
- Tested multiple models:
- Logistic Regression
- Naive Bayes
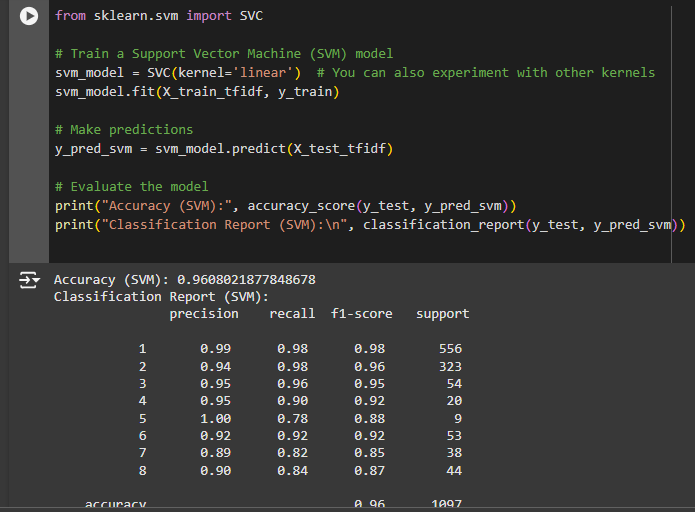
- Support Vector Machine (SVM)
Model Training:
- Split the dataset into training and test sets (usually 70-30 or 80-20).
- Train the model on the training set and evaluate it on the test set.
Evaluation:
- Accuracy: Measures the percentage of correct predictions.
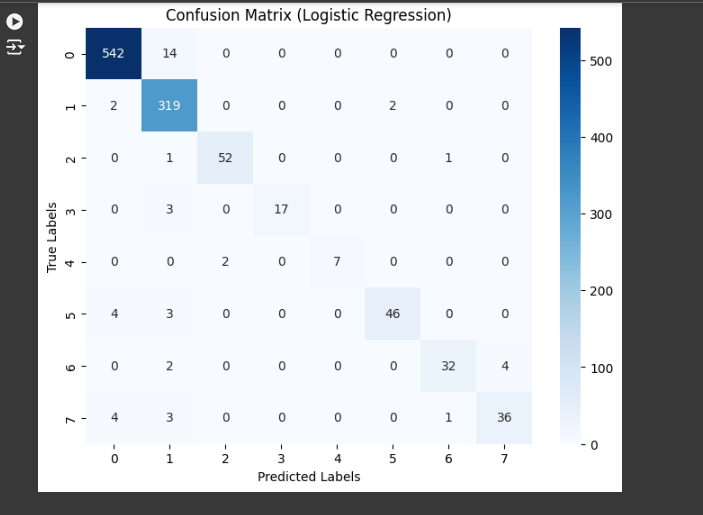
- Confusion Matrix: Shows true vs. predicted labels.
- Precision, Recall, and F1 Score: Measures how well the model performs, especially for imbalanced data.
Results:
The model with the highest accuracy and F1 score was selected. The confusion matrix showed where the model made mistakes, which helped improve the classification process.
Images from the Project